Les inconvénients de l'architecture des réseaux de neurones actuels
Une architecture fixe
Ma principale critique vis-à-vis du ML et des réseaux de neurones artificiels est, pour l'instant, leur extrême rigidité : l'architecture du réseau est toujours figée, généralement designée (designed) par un humain qui va ensuite lancer l'optimisation du modèle afin de maximiser/minimiser une fonction d'objectif en le nourrissant de milliers, de millions voire de milliards de données (le dataset). Chaque fois qu'on va vouloir modifier la structure du réseau, il va falloir lui faire réapprendre tout depuis le début. Parfois on peut prendre un modèle entraîné et l'adapter à un nouveau dataset (fine tuning), en gros on part d'un point d'équilibre dans un optimum local pour reprendre l'entraînement sur un nouvel ensemble de données afin de rendre le modèle tolérant à de nouveaux exemples qu'il n'avait pas vus auparavant.
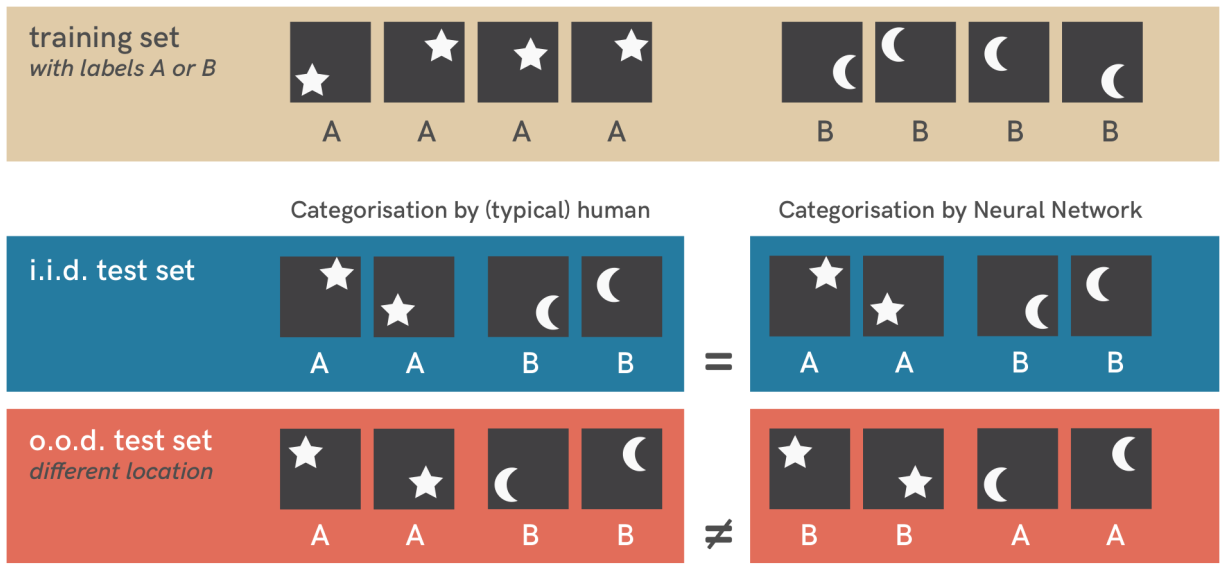
Cela reste malgré tout un processus extrêmement lourd, qui consomme énormément de données, de temps et d'énergie et qui se révèle très peu flexible. On constate de plus assez souvent une incapacité à s'adapter à de nouvelles situations non rencontrées durant l'apprentisasge (out of distribution data), et ces réseaux sont capables de tâches extrêmement réduites (on parle de narrow AI), même s'il on peut difficilement considérer la maîtrise du langage par certains modèles comme étant une tâche réduite.
Incapacité à généraliser
Les tâches réalisées par ces réseaux de neurones sont souvent très spécifiques, on parle de narrow AI, littéralement un IA étroite, qui ne sait traîter que ce pourquoi elle a été conçue et est incapable de généraliser ou de sortir de l'espace restreint des données qu'elle a pu consulter (c'est-à-dire le dataset sur lequel elle a été entraînée).
En gros, ces IA sont faites pour interpoler de nouveaux cas qui ne s'écartent pas trop des cas généraux mais se trompent dès qu'il s'agit de sortir de la distribution (Out Of Distribution).
Même si certaines IA sont impressionnante et ont fait les gros titres de la presse, comme c'est le cas des prouesses de DeepMind avec AlphaGo, il n'en reste pas moins certain que cette IA à qui on aura appris à jouer au jeu de go
sera incapable de faire des crèpes ou enfiler une chemise...
Non seulement elle en sera incapable, mais elle sera incapable d'apprendre à faire des crèpes ou enfiler une chemise : elle n'a été conçue que pour jouer au go.
Conséquences en cas d'émergence d'une conscience
Une conséquence éthique non négligeable doit être prise en compte si d'aventure une "conscience" venait à émerger d'une telle structure fixe de neurones.
Même si je doute fort que ça soit possible, imaginons en effet un instant qu'un être intelligent prenne conscience de lui-même et se rende compte qu'il est un réseau de neurones à l'architecture fixe. Il a alors également conscience de son incapacité totale à changer en quoi que ce soit son architecture, et donc à évoluer et apprendre de nouvelles choses : il a conscience de son incapacité à vivre et à interagir avec le monde extérieur puisqu'à la manière d'un amnésique, il n'en retiendra jamais rien.
On pourrait se dire que ça n'est pas si grave puisqu'après tout, cette entité n'en gardera aucun souvenir. Mais au même titre que nous avons la responsabilité des êtres moins intelligents et moins doués que nous, n'avons-nous pas alors la responsabilité de ne pas laisser souffrir cette entité ? Car il n'y a pas à douter une seule seconde que vivre sans pouvoir grandir ni évoluer est une terrible souffrance ! 1
La modélisation end-to-end
Les problèmes que les réseaux de neurones actuels sont amenés à résoudre sont souvent modélisés avec une approche qu'on appelle End to End qui, semble-t-il, est plus efficace que le découpage manuel en plusieurs sous-tâches.
Cela signifie que si l'on cherche par exemple à générer une image à partir d'une description en texte, comme le fait Dall-E, et même si notre instinct de programmeur nous dicterait de découper cette tâche en plusieurs sous-tâches — une qui va transformer le texte en une représentation générale sous la forme d'un arbre syntaxique par exemple, puis une seconde qui va exploiter cet arbre syntaxique pour générer l'image — on a rapidement découvert qu'il était beaucoup plus efficace de tout modéliser d'un coup en donnant du texte en entrée et en demandant une image en sortie...
Cela semble totalement contre-intuitif à n'importe quel programmeur/ingénieur mais il semblerait qu'en laissant la machine se débrouiller pour trouver un minimum local dans un espace contenant des milliers, voires des millions de dimensions
est plus efficace (et vraisemblablement plus simple) que de tenter d'y mettre nos propres neurones afin d'optimiser ou guider le design du processus. 
C'est d'ailleurs tellement contre-intuitif que je n'ai jamais abandonné l'idée que c'était de la foutaise !
A mon avis, tous les problèmes d'incapacité de la machine à généraliser dans des cas out-of-distribution viennent de là : un entraînement end-to-end sur des images toutes faites sans aucun contrôle possible sur l'espace latent que le NN aura découvert ! Souvent d'ailleurs, les vecteurs dans cet espace latent n'ont aucun sens particulier.
On se rappellera les premiers NNs sur le dataset MNIST (des chiffres de 0 à 9 dans une matrice de 28x28 pixels en niveaux de gris) où même si le modèle distingue parfois des choses qui ont du sens (notamment des filtres qui traitent
les edges), dans les layers supérieurs on s'attendrait "naturellement" à ce que le modèle ait démêlé des structures comme des arcs de cercles, des lignes, des ronds, etc. et s'en servent ensuite pour décomposer des chiffres en morceaux
simples, comme nous semblons le faire nous-même. Or il n'en est rien !
Les "features" que le modèle a isolées correspondent rarement aux features que nous avons apprises étant petits, on voit même souvent des features qui semblent
être des "cheats" ou des raccourcis pour traiter certaines situations, des choses qu'il ne viendrait pas à l'idée d'un humain de stocker comme étant un pattern intéressant à détecter...
Récemment, des progrès semblent être faits 2 du côté de l'assemblage de petits morceaux pour fabriquer des éléments plus gros et ça semble être une approche très prometteuse.
@@@TODO Cas particuliers
Lien sur le thread et la long-tailed distribution https://twitter.com/filippie509/status/1559583211612622848
@@@TODO Natural Language Processing, mais sans sémantique
Lien sur Word2Vec problème
Plein de dimensions dans l'espace latent permet de démêler plein de classes mais PAS de gérer les liens entre les classes => on ne peut pas rapprocher les clasess entre elles pour en calculer le dot product pour mesurer leur similitude, ce qu'essaie de faire Word2Vec, car on cherche à comparer des features/properties/attributes de classes, et elles en ont souvent des dizaines ! C'est un peu aussi vain que demander 1 classe d'objet qui se trouve dans une image là où il y a probablement des milliers de choses à sortir d'une image, déjà en nombre de sujets qui s'y trouvent mais également en terme de niveau de détail selon ce qu'on cherche à synthétiser (ex: une photo gigapixel du Louvre, ou tous les gens qui le visitent et qui sont sur la photo ? Un chien, ou bien ses pattes, ses oreilles, sa truffe et autres morceaux indviduels ?)
-
Des cas cliniques existent et ont été documentés. Par exemple, des patients à qui l'on avait retiré l'hippocampe suite à un cancer et qui ne pouvaient plus former de souvenirs dans la mémoire à court terme. Cf. cette conférence de Veronica O'Keane sur la mémoire ↩
-
https://deoxyribose.github.io/No-Shortcuts-to-Knowledge/ "Representing knowledge as probabilistic programs" ↩